

Bạn có bao giờ tự hỏi làm thế nào mà các công cụ tìm kiếm như Google có thể thu thập và tổ chức hàng tỷ trang web chỉ trong một khoảng thời gian ngắn? Hay làm cách nào mà các trang web so sánh giá có thể cập nhật nhanh chóng từ nhiều cửa hàng trực tuyến khác nhau? Tất cả đều bắt nguồn từ một kỹ thuật quan trọng được gọi là crawl data website (thu thập dữ liệu trang web). Qua bài viết này, chúng ta sẽ cùng khám phá chi tiết về crawl data, quy trình hoạt động của nó, cũng như ứng dụng và lưu ý quan trọng khi thực hiện.
 Crawl là gì? Cơ chế hoạt động của crawl data website
Crawl là gì? Cơ chế hoạt động của crawl data website
Crawl là gì?
Crawl là quá trình mà các công cụ tìm kiếm như Google, Bing hoặc các hệ thống thu thập dữ liệu khác sử dụng để quét và thu thập thông tin từ các trang web trên Internet. Các bot hay spider sẽ truy cập vào website, đọc nội dung, thu thập dữ liệu và lưu trữ hoặc lập chỉ mục, từ đó giúp công cụ tìm kiếm hiểu rõ hơn về nội dung trang web và đánh giá mức độ liên quan của nó đối với các truy vấn tìm kiếm của người dùng.
 Crawl là gì?
Crawl là gì?
Sự khác biệt giữa crawl và scrap
Mặc dù crawl và scrap đều liên quan đến việc thu thập dữ liệu từ web, nhưng chúng có mục tiêu và phương thức khác nhau:
- Crawl (Thu thập dữ liệu): Là quá trình mà bot tự động duyệt qua hàng loạt trang web, khám phá và lập chỉ mục nội dung theo cách tổ chức nhằm đảm bảo các trang được tìm thấy và xếp hạng bởi công cụ tìm kiếm.
- Scrap (Trích xuất dữ liệu): Tập trung vào việc lấy thông tin cụ thể từ một trang web, có thể là nội dung bài viết, hình ảnh hay dữ liệu sản phẩm. Quá trình scrap thường yêu cầu xử lý dữ liệu riêng biệt và chi tiết hơn.
 Crawl website
Crawl website
Quy trình hoạt động của crawl
Crawl là một quá trình quan trọng giúp công cụ tìm kiếm phát hiện và lập chỉ mục nội dung trên Internet. Dưới đây là các bước cụ thể trong quy trình này:
1. Khởi đầu từ danh sách URL (Seed URLs)
Công cụ tìm kiếm sẽ bắt đầu bằng một danh sách URL có sẵn, thường bao gồm các trang web phổ biến hoặc đã được biết đến. Những URL này có thể được thu thập từ nhiều nguồn:
- Các trang được gửi trực tiếp qua Google Search Console.
- Các trang đã được lập chỉ mục trước đó.
- Danh sách URL từ sitemap XML của website.
Ví dụ: Google có thể khởi đầu từ trang chủ của một tờ báo lớn và từ đó khám phá các đường link khác trên trang này.
2. Khám phá liên kết (Link discovery)
Khi bot truy cập vào một trang, nó sẽ quét nội dung và tìm kiếm các liên kết đến các trang khác. Các liên kết này giúp bot mở rộng phạm vi thu thập dữ liệu bằng cách:
- Dò tìm các thẻ chứa liên kết nội bộ và liên kết ngoài.
- Thu thập URL từ sitemap XML hoặc RSS Feed.
- Kiểm tra các liên kết từ các trang có độ tin cậy cao.
Ví dụ: Nếu một bài viết trên trang A có liên kết trỏ tới bài viết trên trang B, bot sẽ phát hiện trang B và thêm vào danh sách crawl.
 Crawl data
Crawl data
3. Kiểm tra robots.txt và meta tag
Trước khi giới thiệu nội dung, bot sẽ kiểm tra tệp robots.txt để biết các trang được phép hoặc không được phép thu thập. Ngoài ra, nó cũng kiểm tra các thẻ meta như noindex và nofollow để xác định những chỉ dẫn cấm thu thập hoặc lập chỉ mục.
4. Thu thập nội dung (Data extraction)
Bot sẽ tải nội dung trang web, bao gồm văn bản, hình ảnh và mã nguồn HTML. Nội dung này sẽ được xử lý nhằm trích xuất dữ liệu cần thiết, chẳng hạn như:
- Tách phần nội dung chính khỏi quảng cáo và sidebar.
- Nhận diện hình ảnh, video và các file liên quan.
- Trích xuất dữ liệu có cấu trúc như JSON-LD hoặc Microdata.
 Crawl data website
Crawl data website
5. Lọc và phân loại nội dung
Công cụ tìm kiếm sẽ lọc và phân loại nội dung thu được dựa trên các tiêu chí như mức độ liên quan, chất lượng nội dung và tính cập nhật. Những dữ liệu không đáp ứng các tiêu chí này sẽ được loại bỏ.
6. Lập chỉ mục (Indexing)
Sau khi thu thập và xử lý nội dung, dữ liệu sẽ được đưa vào hệ thống lập chỉ mục. Khi người dùng tìm kiếm từ khóa liên quan, công cụ tìm kiếm sẽ lấy dữ liệu từ chỉ mục này để hiển thị kết quả phù hợp.
 Crawl data from website
Crawl data from website
Các yếu tố ảnh hưởng đến quá trình crawl
Quá trình crawl không chỉ đơn thuần là việc bot ghé thăm một trang web mà còn phụ thuộc vào nhiều yếu tố như:
1. Cấu trúc website
Một website có cấu trúc rõ ràng và hệ thống phân cấp tốt giúp bot dễ dàng thu thập dữ liệu từ các trang quan trọng. Nếu nội dung bị ẩn sâu hoặc không có liên kết dễ dàng tiếp cận, khả năng thu thập sẽ bị ảnh hưởng.
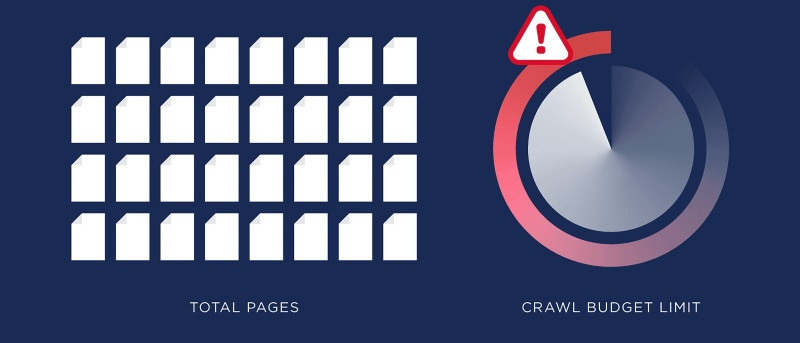
2. Crawl budget
Crawl budget là số lượng trang mà bot sẵn sàng truy cập trong khoảng thời gian nhất định. Trang web lớn với hàng nghìn URL nên phải quản lý crawl budget để đảm bảo rằng các trang quan trọng được thu thập đúng hạn.
3. Robots.txt và quy định chặn crawl
Tệp robots.txt cung cấp hướng dẫn cho bot về các phần được phép truy cập. Việc xử lý tệp này hiệu quả giúp bảo vệ các khu vực không công khai và giảm lãng phí crawl budget.
 Crawl dữ liệu
Crawl dữ liệu
Ứng dụng của crawl data trong thực tế
Crawl data có rất nhiều ứng dụng trong thực tế, bao gồm:
1. SEO (Search Engine Optimization)
Crawl giúp các công cụ tìm kiếm lập chỉ mục chính xác nội dung của website. Nếu các bot có thể quét các liên kết nội bộ và phân tích nội dung, các chuyên gia SEO sẽ có cơ hội tối ưu hóa cấu trúc và nội dung để cải thiện thứ hạng tìm kiếm và tăng cường lượng truy cập tự nhiên.
2. Data scraping
Crawl data còn được sử dụng rộng rãi trong việc tự động thu thập thông tin, như giá cả sản phẩm, đánh giá hay nội dung bài viết từ nhiều trang khác nhau. Điều này rất hữu ích cho các nghiên cứu thị trường và phân tích dữ liệu.
3. Phát hiện lỗi website
Crawl cũng giúp phát hiện các vấn đề kỹ thuật như lỗi 404, vấn đề về tốc độ tải trang và cấu trúc nội dung. Từ đó, các nhà phát triển có thể nhanh chóng xử lý và cải thiện trải nghiệm người dùng.
4. Aggregators
Các dịch vụ tổng hợp thông tin từ nhiều nguồn để cung cấp cho người dùng nền tảng nhất định để truy cập thông tin nhanh và tiện lợi. Nhờ vào crawl data, họ có thể xử lý và kết hợp dữ liệu từ nhiều nguồn khác nhau.
 Data crawl
Data crawl
Các công cụ crawl data website phổ biến
Chọn công cụ crawl phù hợp là rất quan trọng để tối ưu hóa quá trình thu thập dữ liệu. Dưới đây là một số công cụ điển hình:
- Googlebot: Công cụ thu thập chính của Google, sử dụng để quét và lập chỉ mục thông tin trên các trang web.
- Bingbot: Tương tự Googlebot nhưng dành cho công cụ tìm kiếm Bing, hỗ trợ tối ưu hóa cho trang web trên nền tảng này.
- Scrapy: Một framework mã nguồn mở cho phép người dùng xây dựng web crawlers tùy chỉnh.
- Screaming Frog SEO Spider: Công cụ SEO giúp phân tích và tối ưu hóa các yếu tố liên quan đến SEO trên trang web.
 Công cụ crawl
Công cụ crawl
Những lưu ý quan trọng khi crawl dữ liệu
Khi thực hiện quá trình crawl, hãy chú ý đến những điều sau:
- Tuân thủ tệp robots.txt: Kiểm tra tệp này để xác định những phần nào được phép và không được phép truy cập, đảm bảo hoạt động hợp pháp.
- Quản lý tần suất yêu cầu: Gửi quá nhiều yêu cầu trong thời gian ngắn có thể gây quá tải cho máy chủ, dẫn đến việc bị chặn.
- Xử lý trang yêu cầu đăng nhập: Các trang yêu cầu xác thực cần được xem xét cẩn thận để không vi phạm quy định.
- Đảm bảo đảm đạo đức và luật pháp: Tuân thủ quyền riêng tư và luật bảo mật khi thu thập dữ liệu là điều tối cần thiết.
 Crawl dữ liệu website
Crawl dữ liệu website
Một số câu hỏi thường gặp về crawl data website
1. Tại sao có nhiều trang web không được Google crawl?
Có thể vì sử dụng thẻ “noindex”, yêu cầu xác thực hoặc thiếu liên kết nội bộ.
2. Điều gì xảy ra nếu website không được crawl dữ liệu?
Trang sẽ không xuất hiện trong kết quả tìm kiếm, dẫn đến giảm lượng truy cập tự nhiên.
3. Khi nào nên sử dụng công cụ crawl của bên thứ ba?
Khi cần phân tích SEO, giám sát trang web hoặc thu thập dữ liệu cho nghiên cứu.
 Thu thập dữ liệu website
Thu thập dữ liệu website
Crawl data website không chỉ giúp các công cụ tìm kiếm cung cấp kết quả chính xác cho người dùng, mà còn hỗ trợ doanh nghiệp tối ưu hóa nội dung trực tuyến của mình. Hãy khám phá thêm về lĩnh vực này trên trang web shabox.com.vn để nâng cao kiến thức và khả năng của bạn trong việc quản lý dữ liệu trên Internet.


